
基幹システムにAIを入れたい——その気持ちはよくわかる。しかし、AIは賢いだけでは足りない。その会社の言葉、ルール、データの意味が分かって初めて使えるのだ。
※本記事は、日経クロステックの記事を参考に、筆者なりの解釈でまとめたものです。
最新AIを入れれば、基幹システムも賢くなる——その誤解
会計、受発注、在庫、請求といった基幹領域では、企業ごとのルールに従って、唯一無二の正解を、しかも素早く出すことが求められます。インターネット上の一般知識を学習したAIをそのまま持ち込んでも、安心して使えるとは限りません。
たとえば「売上」という言葉ひとつ取っても、税抜なのか税込なのか、受注時点なのか売上計上時点なのか、返品を含むのか含まないのかで意味は変わります。人間の担当者なら文脈で補えますが、AIは定義がなければ推測するしかありません。推測が混じる時点で、基幹システムでは危険です。
Text-to-SQLが本番で定着しにくい、本当の理由
「今月の粗利率が前年同月比で下がった要因は?」と聞けば、AIはそれらしい答えを返せるかもしれません。けれども、粗利率の定義、売上の定義、集計粒度、基準日、除外条件が曖昧なままでは、AIはもっともらしいが誤った集計を返す可能性があります。
自然言語分析が本番で定着しにくい理由は、AIモデルの性能不足だけではない。
むしろ本質的な問題は、データの意味が暗黙知のまま残っていることにある。
テーブル定義書だけでは足りない
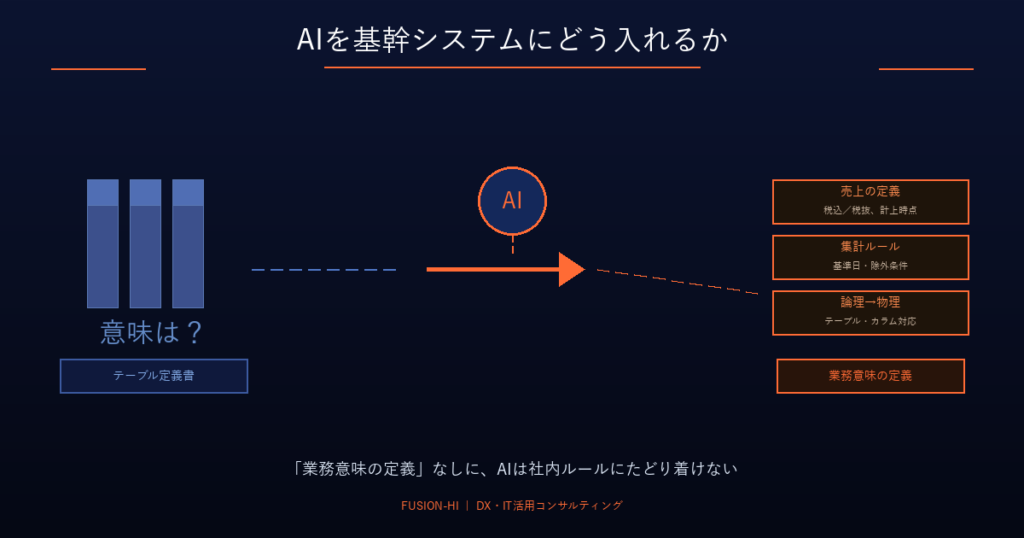
一般的なテーブル定義書にあるのは「どう格納するか」という技術情報であり、「それが業務上何を意味するのか」という意味情報ではありません。AIに必要な情報はこれだけです。
| 業務上の意味 | この項目は何を表すのか。何を含み、何を含まないのか |
| 用語の区別 | 似た用語(例:売上/売上高/計上額)との違いは何か |
| 計算ルール・時点基準 | どの時点を基準にするのか。例外時にはどう扱うのか |
| 論理→物理の対応 | 業務概念が物理的にはどのテーブル・カラムにひも付くのか |
こうした情報が揃ってはじめて、AIは「社内の言葉」と「実データ」を正しく結び付けられるようになります。
AIの主戦場は「トランザクション処理」ではない
基幹システムで求められるのは、1円違わない確定結果です。決定的なトランザクション処理は引き続きアプリケーションロジックが担うべきであり、AIの主戦場はそこではありません。
| 意味解釈・検索 | 利用者の質問を解釈して適切なデータ資産を探す |
| SQL生成・説明 | 定義に沿ってSQLを組み立て、帳票差異を説明する |
| 用語案内・探索 | 用語の意味を案内し、影響範囲を洗い出す |
基本設計の段階で「意味」を残しておくことの価値
多くのプロジェクトでは、機能仕様やテーブル定義までは作り込んでも、意味情報は担当者の頭の中に残りがちです。この情報を基本設計時に整理しておけば、後工程でAI活用の土台として再利用できます。
- 受け入れテスト:要件定義をもとにAIが正常系・異常系・境界値のテスト観点を洗い出す
- 自然言語BI:用語定義と集計ルールがあれば、自然言語の質問を社内ルールに沿って解釈できる
- 将来の再構築:刷新で最も苦しいのは「現行の意味が失われていること」。今残すことは次の刷新への備えでもある
AIを基幹システムに入れるとは、チャットUIを追加することでも、最新モデルを導入することでもない。
AIが間違えないように、企業固有の意味を先に整えること——それが本当のAI活用の出発点だ。
※ 本記事は、日経クロステック「AIを基幹システムに組み込む際のデータ管理」を参考に、筆者なりの解釈でまとめたものです。